简介
哈希表(散列表)是根据(key,value)进行直接访问的数据结构,也就是说一张哈希表通过把 key 映射到表中的一个位置来访问某条记录,达到加快查找速度的目的。理想状态的时间复杂度可以降到 O(1),是一种空间换时间的算法例子。
哈希表的实现,主要需要解决两个问题:
1. 哈希函数
2. 地址冲突
** **
1.哈希函数
哈希函数的作用,是使不同的输出值得到一个固定长度的消息摘要。理想的哈希函数对于不同的输入应该产生不同的结构,同时散列结果应该具有同一性(输出值尽量均匀)和雪崩效应(微小的输入值变化使得输出值发生巨大的变化。)
哈希函数: position = f(key)
下面几个函数都可以成为哈希函数:
(1) f(x) = x mod 16;
(2) f(x) = (x2 + 10) * x;
(3) f(x) = (x | 0×0000FFFF) XOR (x >> 16)
但上面的函数并未做到两点效果:
①. 输出值均匀(对不同的key,映射到地址集中的任一地址的概率应相等)
②. 雪崩效应( | df(x) / dx |>> 1 )
综合看来,上面三个中 ,第三个比较满足理想哈希函数的要求。
f(x) = (x | 0x0000FFFF) XOR (x >> 16);
2.地址冲突
但是理想的哈希函数是难达到的,实际应用的哈希函数并不完美。当两个不同的输入值产生同一个输出值时,就产生了“碰撞”。此时需要解决冲突。
常见的冲突解决办法有两种:
2.1 链地址法
2.2 开放定址法
2.1 链地址法
链地址法的基本思想是,为每一个哈希值建立一个单链表,当冲突发生的时候,就将记录插入到链表中。
具体做法是: 如果哈希表空间为 0 ~ m-1, 设置一个由 m 个指针分量组成的一维数组 ST[m], 凡是哈希地址为 i 的数据元素都插入到头指针为 ST[i] 的链表中。这种做法近似于邻接表的基本思想。且这种方法适合于冲突比较严重的情况。
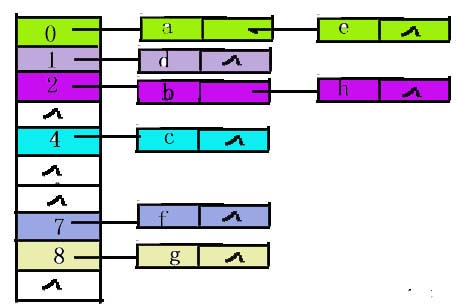
例:
设现在有 8 个元素{a, b, c, d, e, f, g, h},采用某种哈希函数得到的地址分别是:{0,2,4,1,0,8,7,2}. 当哈希表的长度为10时,采用链地址法解决冲突的哈希表如下图所示:
*2.2 开放定址法*
开放定址法的基本思想是:当地址冲突发生时,按照某种方法继续探测哈希表中的其他存储单元,直到找到空地址为止。此过程可用下面的式子描述:
H i ( key ) = ( H ( key )+ d i ) mod m ( i = 1,2,…… , k ( k ≤ m – 1))
其中 H(key) 为关键字 key 的直接哈希地址,m 为哈希表的长度,di 为每次再探测时的地址增量。
采用这种方法,首先计算出元素的直接哈希地址 H(key),如果该存储单元已经被其他元素所占用,那么继续查看地址为 H(key) + d2 的存储单元,如此重复直到找到某个为空的存储单元为止。将关键字为 key 的数据元素存放到该单元。
增量 d 可以有不同的取法,并根据其取法有不同的称呼:
( 1 ) d i = 1 , 2 , 3 , …… 线性探测再散列;
( 2 ) d i = 1^2 ,- 1^2 , 2^2 ,- 2^2 , k^2, -k^2…… 二次探测再散列;
( 3 ) d i = 伪随机序列 伪随机再散列;
3. 一个 C 的实现
运行结果:
(注:使用VS运行时,由于strcpy的安全性,IDE不允许直接用,需要在project -> [project_name]properties -> C/C++ -> Preprocessor的第一行配置中,添加 _CRT_SECURE_NO_WARNINGS 声明)

#include<string.h>
#include<stdio.h>
#include<stdlib.h>
typedef struct _node {
char *name;
char *desc;
struct _node *next;
}node;
#define HASHSIZE 101
static node* hashtable[HASHSIZE];
void inithashtable()
{
int i;
for (i = 0; i < HASHSIZE; i++) {
hashtable[i] = NULL;
}
}
unsigned int hash(const char *s)
{
unsigned int h = 0;
for (; *s; s++) {
h = *s + h * 31;
}
return h % HASHSIZE;
}
node* lookup(const char *n)
{
unsigned int hi = hash(n);
node* np = hashtable[hi];
for (; np != NULL; np = np->next) {
if (!strcmp(np->name, n)) {
return np;
}
}
return NULL;
}
char* m_strdup(const char *o)
{
int l = strlen(o) + 1;
char* ns = (char*)malloc(l * sizeof(char));
strcpy(ns, o);
if (ns == NULL) {
return NULL;
} else {
return ns;
}
}
char* get(const char* name)
{
node* n = lookup(name);
if (n == NULL) {
return NULL;
} else {
return n->desc;
}
}
int install(const char* name, const char* desc)
{
unsigned int hi;
node* np;
if ((np = lookup(name)) == NULL) {
hi = hash(name);
np = (node*)malloc(sizeof(node));
if (np == NULL)
return 0;
np->name = m_strdup(name);
if (np->name == NULL)
return 0;
np->next = hashtable[hi];
hashtable[hi] = np;
} else {
free(np->desc);
}
np->desc = m_strdup(desc);
if (np->desc == NULL)
return 0;
return 1;
}
/**
\* a pretty useless but good debugging function, which simply displays the hashtable in (key, value) pairs.
*/
void dsiplaytable()
{
int i;
node *t;
for (i = 0; i < HASHSIZE; i++) {
if (hashtable[i] == NULL) {
printf("()");
} else {
t = hashtable[i];
printf("(");
for (; t != NULL; t = t->next) {
printf("(%s.%s) ", t->name, t->desc);
}
printf(".)");
}
}
}
void cleanup()
{
int i;
node *np, *t;
for (i = 0; i < HASHSIZE; i++) {
if (hashtable[i] != NULL) {
np = hashtable[i];
while (np != NULL) {
t = np->next;
free(np->name);
free(np->desc);
free(np);
np = t;
}
}
}
}
int main()
{
int i;
const char* names[] = {"name", "address", "phone", "k101", "k110" };
const char* descs[] = {"Sourav", "Sinagor", "26300788", "Value1", "Value2"};
inithashtable();
for (i = 0; i < 5; i++) {
install(names[i], descs[i]);
}
printf("Done\n");
printf("If we didnt do anything wrong..We should see %s\n", get("k110"));
install("phone", "9433120451");
printf("Again if we go right, we have %s and %s\n", get("k101"), get("phone"));
cleanup();
system("pause");
return 0;
}